この記事は約6分で読めます

はじめに
現代のビジネス環境において、紙媒体の情報をデジタル化し、業務効率を向上させることは避けられない課題となっています。特に請求書、見積書、契約書など、各社独自のフォーマットで発行される紙文書は、単純なスキャンや既存のOCRツールでは構造化が難しく、データ処理や分析に大きな負担をもたらしています。
バックオフィス業務では、紙資料の処理に依然として多くの工数と人的リソースが必要です。文字情報の取得だけでなく、文書全体の文脈や意味を理解した上で、必要な情報を自動的に構造化できれば、業務の効率化と品質向上を同時に実現できます。
本記事では、生成AIを活用して紙媒体の文書を「意味的に(セマンティック)解釈」することで、従来のOCRの課題を克服し、柔軟かつ高精度な情報抽出を実現する新手法「セマンティックOCR」についてデモを交えて解説します。
※ここでいうセマンティックとは、生成AIが持つ高度な言語理解能力を活用し、文書の内容や構造を文脈に基づいて解釈することを指します。従来のOCRが単なる文字認識に留まるのに対し、セマンティックOCRは文書の意味や目的を理解した上で情報を抽出できます。
Algomaticでは、生成AI人材育成研修・Dify研修・AIエージェント構築研修・AI駆動開発研修を通じて、現場で使えるスキルを体系的に学べます。
>>AI研修プログラムを見る
従来OCRの業務適用における課題
OCR(Optical Character Recognition)とは、紙などに印刷または手書きされた文字をスキャンやカメラ撮影によって画像データとして取り込み、その画像に含まれる文字情報をコンピュータが「テキストデータ」として読み取る技術を指します。紙の文書を電子化する際に重要な技術で、通常は文字の形をパターンマッチングや機械学習によって解析し、テキストに変換します。これにより、印刷物や手書き文章の検索や編集が可能になり、デジタル業務の効率化に役立ちます。ただし、既存のOCRには下記のような課題があります。
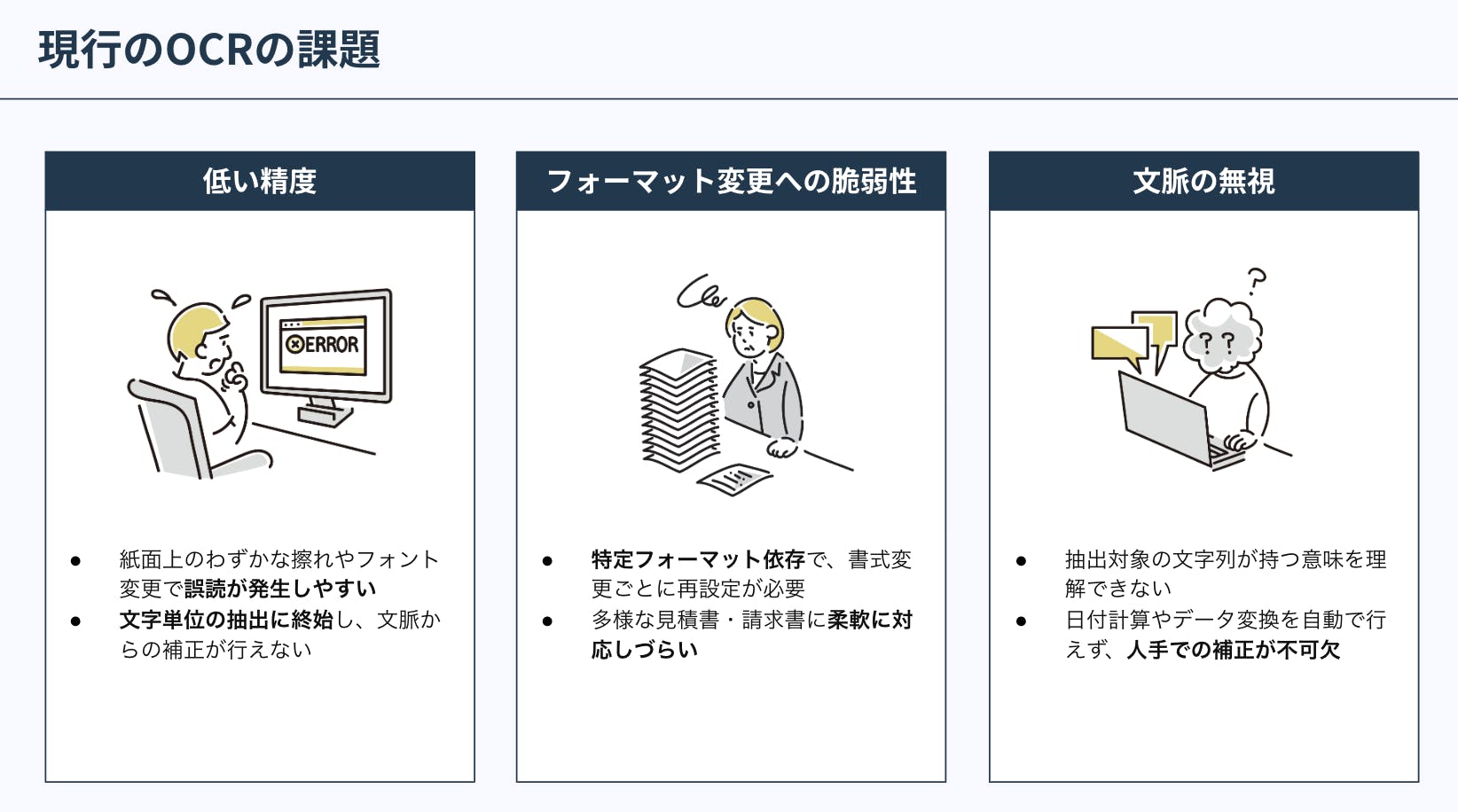
精度が低い
既存の多くのOCRはパターン認識による文字の機械的抽出に依存しているため、紙面上で文字が擦れたりフォントが変わったりすると誤読が発生しやすくなります。人間であれば文脈から欠損を補い、意味を推察できますが、OCRは文字単位の読み取りに終始するため、文脈を理解した補正ができません。
フォーマット変更への脆弱性
多くのOCR処理は、特定のフォーマットに基づくテンプレートや座標指定に従ってデータを抽出します。そのため、書式が少し変わっただけでも再設定が必要となり、企業ごとに異なる見積書・請求書フォーマットが混在する現場では柔軟な対応が困難です。
文脈を理解できない
OCRは抽出対象の文字列の意味を理解していません。例えば「期日:発行日から2週間後」という表現があっても、OCRは「2週間後」という文字列を取り出すだけで、実際の日付計算やデータ変換は人間が行う必要があります。その結果、単純作業の削減には限界があり、デジタル化後も人手による補正が必要です。
解決策としての「セマンティックOCR」
これらの課題に対し、私たちは生成AIを活用した「セマンティックOCR」を解決策として提示します。このシステムは、紙面の画像をマルチモーダルモデルで処理し、文字情報の抽出と同時に、LLM(大規模言語モデル)による高度な文脈理解を実現します。これにより、単なる文字の認識を超えて、文書の意味や目的を正確に把握し、情報を効率的に整理することが可能になります。
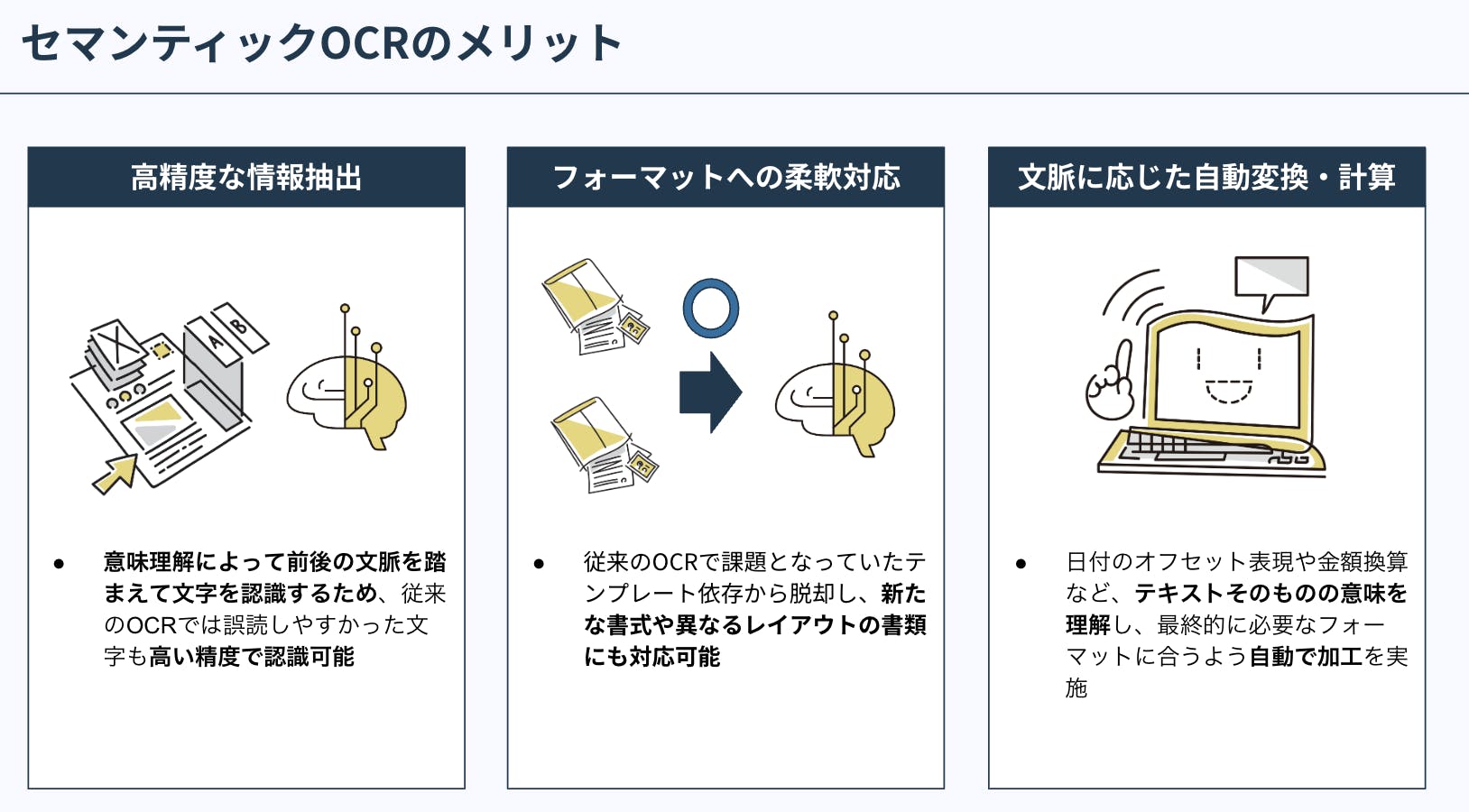
セマンティックOCRの特長・メリット
- 高精度な情報抽出:文脈を踏まえることで、従来のOCRでは誤読しやすい文字も正確に認識。
- フォーマットへの柔軟な対応:テンプレート依存から脱却し、新たな書式や異なるレイアウトの書類にも対応可能。
- 文脈に応じた自動変換・計算:日付のオフセット表現や金額換算など、テキストを理解し、必要な加工を自動的に実施。
デモ:意味理解に基づく見積書データの抽出・構造化
ここでは、2つの異なるフォーマットの見積書を用意し、セマンティックOCRを適用するデモ動画を紹介します。以下の3点がデモの注目すべきポイントです。
1. 意味を理解したデータ抽出と自動変換
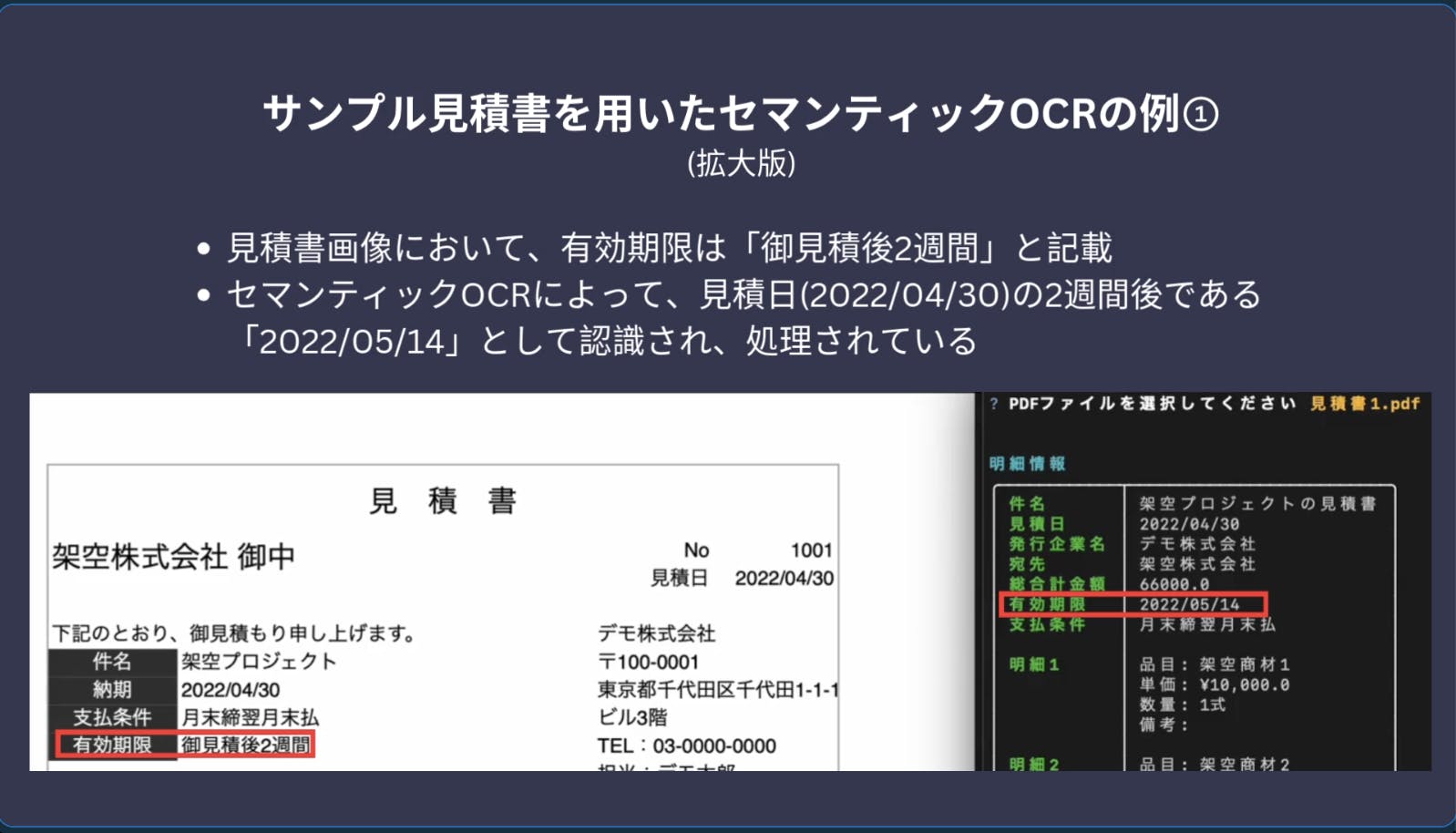
例えば、見積書に「有効期限:御見積後2週間」という記載がある場合、セマンティックOCRは単なる文字認識を超えて、この期間表現を理解し、具体的な日付へと自動的に変換します(例:2022/04/30→2022/5/14)。これにより、後続の業務システムでそのまま活用できる形式でデータを出力できます。
2. フォーマットに依存しない柔軟な処理
1つ目と2つ目の見積書はレイアウトや文字スタイルが異なりますが、セマンティックOCRはこれらを柔軟に読み取り、自動で構造化します。
異なる企業から受け取る様々な様式の見積書に対しても、テンプレート設定なしで必要な情報を正確に抽出できます。レイアウトや表記方法が変わっても、AIが文書の構造を理解して適切に処理します。
3. 標準化された構造データの生成
抽出されたデータは、ERPシステムやBIツールとの連携を考慮した標準フォーマットで出力されます。文脈を考慮した意味理解により、データの整合性が保たれ、システム間連携がスムーズに行えます。
デモの総括
このデモにより、セマンティックOCRが従来の紙媒体処理における課題を効果的に解決できることを実証しました。文脈理解による高精度な情報抽出、多様なフォーマットへの柔軟な対応、そして意味を理解した自動データ変換により、業務効率を大幅に向上させることが可能です。さらに、業務要件に応じてプロンプトやワークフローをカスタマイズすることで、より高度で包括的なデジタル化ソリューションを実現できます。
おわりに
本記事では、紙ベースの情報デジタル化における従来OCRの課題(精度、フォーマット対応、文脈理解の欠如)を整理し、生成AIを活用した「セマンティックOCR」による解決策を提示しました。
セマンティックOCRの導入は、紙媒体のデジタル化プロセスにおける業務効率と精度を大幅に向上させ、従来の手作業による負担を軽減します。これにより、企業は人的リソースをより高付加価値な業務へと再配分し、組織全体の生産性向上を実現することが可能となります。
このような業務改革の効果は、バックオフィス業務にとどまらず、製造業界の設計書や物流業界の在庫管理表など、あらゆる紙資料を扱う業務に適用できます。以上を踏まえ、紙媒体のデジタル化においては、従来のOCRから一歩進んだ、セマンティックOCRの活用をぜひご検討ください。
弊社のAI Transformation(AX)カンパニーでは、今回ご紹介したセマンティックOCRによる紙媒体のデジタル化以外にも、生成AIを活用した業務効率化のご支援を多数展開しています。お客様のニーズに合わせた最適なソリューションを提案し、AI活用による業務変革(AX)をサポートいたします。お気軽にお問い合わせください。
Algomaticでは、生成AI人材育成研修・Dify研修・AIエージェント構築研修・AI駆動開発研修を通じて、現場で使えるスキルを体系的に学べます。
>>AI研修プログラムを見る



